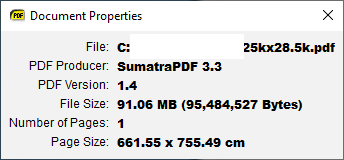
Hello,
Background:
this content is average in professional prepress, high-end litho printing or grand format outdoor printing. The content and expectation is not for the average home/office user where previewing at 72/96dpi may be sufficient. Complex trapping https://en.wikipedia.org/wiki/Trap_(printing) , proofing and color seperation processes take place as part of the workflow. Viewing/Proofing with SPDF is just a small part of that workflow.
The offset presses can go to far higher resolutions than my sample file and having the ability to preview a high resolution file is very valuable. I use spdf 3.1.2 for the previewing of such high-res files without any problems.
Comments about your reply:
Firefox is a browser, not designed as a high res pdf viewer and its memory management is never expected to render such content. I am not surprized that it fails to finish rendering the file. I dont expect it to render it either.
every version of muPDF fails to allocate enough memory too, even on a system with 16GB ram because it is designed lightweight and for screen preview - but still tries to allocate one giant bitmap at a resolution that is not needed. I am in contact with the developers to see if the design can be reviewed. Work in progress.
Adobe Acrobat opens the file by reading in horizontal stripes, in 45 seconds on an intel i3, quad core, 3GHZ CPU, with Zoom = Fit Page. Total memory use is around 50MB, almost nothing. The rendering time may be considered “exceptionally slow” for users that are used to normal MS Office documents or regular vector cad files, but for print professionals working with high-res raster and RIPs, 45 seconds rendering time for preview is totally reasonable and acceptable.
SPDF 3.1.2 opens the file in 32 seconds on the same CPU with Zoom = Fit page, under 100mb memory use. This is a brilliant result and outperforms the result for speed of a product of a multi billion dolar corporation.Well done!
Ghostscript, also an industrial strenght tool (and interestingly also from Artiflex, same as mupdf) IS able to rasterize the file to PNG or JPG with very little memory use. 16 seconds for 36dpi and 18 seconds for 96dpi on the same PC. Memory use is under 30mb throughout the process. This is the fastest method to generate a low res preview. But building a smooth viewer with zoom and scroll and pan, zone extractiong etc, like SPDF by stitching these images or rasterizing the needed zone on demand is a pain and a massive project by itself. I really do not want to try reinventing the wheel when SPDF 3.1.2 does such a great job already. Maybe some rendering code in SPDF could incorporate GS (only when needed) instead of muPDF. GS is usually faster for pure raster content, while muPDF is far faster for vector.
The file I supplied is just one example, there are hundrets of other cases where very large presentation posters are printed and need high-res proofing, output is sometimes on 60inch wide and 200+ inch long rolls at 600/800/1200 dpi resolution. Again, this is not the world of casual home/office users. This is industrial strenght. Some printing is done on UV Resistent Latex devices and a 53 feet Truck is wrapped with a canvas like water resistent material. The printed sheet is a single piece per side. There are many other use cases for high resolution raster graphics. High end Printing industry works in CMYK colorspace (32bit color) because that is how the physical printing process works. Preview with RGB is Ok for some cases, when color accuracy is not critical RGB (24bit) files are used as well, but at the end either the RIP or the Firmware or another software converts those 3 RGB planes into 4 planes of CMYK. This explanation is in response to your comment “Any reason its not less colors and stored as 100-300dpi?” Another factor is that many times design studios or third parties create and submit a rasterized file. I have no control over the resolution but would like to preview it without tampering with the original. Here is just one example possible output device. Look at the spec sheet https://www.topazeng.com/hp-specifications/pagewide-xl8000-specs.pdf
1200x1200dpi native resolution at 40 inch wide and a few hundret feet length!
Your suggestion to copy and paste between applications, from Sumatra (I assume 3.1.2 - because 3.2 chokes) over Clipboard to Irfanview then resave with less colors and dpi is a valid workaround if someone is willing to do that manually and one off, and is willing to loose the resolution.
The concerns with loosing resolution are
- no proper trapping check
- loss of detail in preview when zoomed in for proofing
- in some different workflow cases user must zoom into the content at 150-200% , mark an area with the control+mouse feature of SPDF (which is brilliant that it takes vector text if the object is TTF Font, or the Image) and copy the area - OCR text recognitation runs automatically over the extracted image if no vector object is found and extracts metadata out of the content.
All of these functions suffer or do not work at all if the original is reduced to something like 96dpi
Also, all the conversions you suggested would need to be done from either command line or some sort of code. The user won’t be able to go home if he has to do this manually.
As you can see I tried to be very detailed about the use case and tried to explain the need for high res preview and zoom ability.
I don’t know the C++ inner workings of SPDF and muPDF enough to comment if my suggestions below are feasiable or not, but SPDF 3.1.2 is able to render such highres files, at any zoom % without any problems, in reasonable time, and I really do not want to loose the upcoming releases of SPDF because there has been a step backwards in memory management which SPDF 3.2 seems to be.
-
there is no requirement to push the entire image into static RAM at a single time if the memory requirement is high. At the end, the image is drawn on screen anyways, into the viewable area of the SPDF process. A Full HD Monitor has a pixelsize of 1920x1080. Even High end Monitors have ‘only’ 3,840x2,160 pixel resolution - those numbers are very little compared to the pixel size of my supplied sample file (27,156x43,511). It is sufficient if SPDF decodes and renders the viewable area, and not waste time on parts that are not going to be drawn on screen anyways, which is still evident even in SPDF 3.1.2 when you zoom in at 200/400%).
-
SPDF could check for “safe” available free memory, if there is anough free memory and it can be allocated for the whole image use it because the rendering will finish faster. If there is not enough memory, either work in stripes (Y direction like Adobe) (and only on the X coordinate ranges that fall within the viewable zone of the Monitor/Display zone) or work in Blocks/Chunks, again only within the viewable zone of the monitor, which is what SPDF 3.1.2 seems to be doing when I observe how it draws and sharpens the blocks one by one when zoomed in at 300% on a high res image.
-
I work with the libvips library as well. https://github.com/libvips/libvips
it can work with and paste together images from different sources at 100,000x100,000pixels, 32 bit!. With very reasonable memory usage, using block by block processing or what they call “streaming” mode. Maybe the approaches there could give sime ideas to improve SPDF rendering as well.
My goal by writing this is with the hope that the great working memory function in 3.1.2 does not take a hit for the worst because I will be staying at SPDF 3.1.2 and will probably miss out on future development and new functions of SPDF.
Best Regards,