Pdf to text is a variable goal
Pdf pages can be textual vector objects (glyphs / characters / words ) placed via coordinates within a “page zone” thus converting to sequential plain text in those cases is difficult
The characters could be simply pixel images and need OCR conversion to letters in word sequences.
Those tasks are usually beyond the scope of a viewing application, so only in a few cases SumatraPdf can simply save some pages already stored as text into a text file
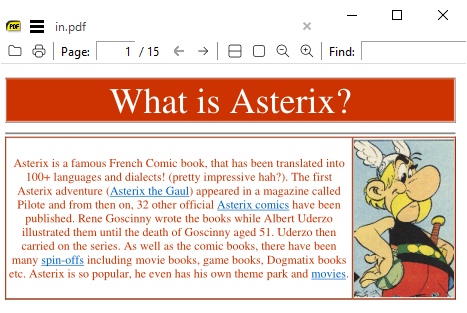
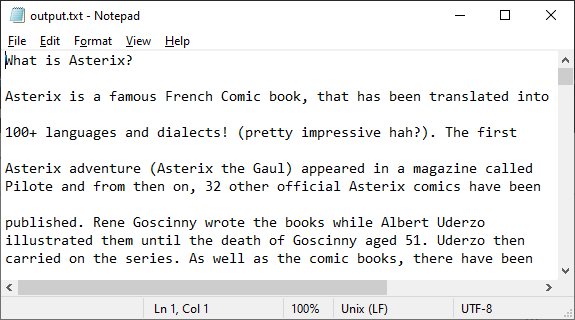
Take this example first paragraph as saved using any viewer app from the pdf
Points to note
The first three lines of exported textual output are not noticeably visible in the PDF until the end of page, that’s a common feature of PDF files ( what you see is NOT the order in which it is stored, especially needed for accessibility users )
Graphic lines and images are not exported as text. Audio readers may need hidden descriptive text tags.
Also (as plain text) the vertical text needs to be simply exported as horizontal words.
So it is best to use SumatraPDF to export pages or whole file to a dedicated 3rd party converter, selecting from different apps based on the type of source.
SumatraPDF is based on MuPDF which has OCR capability but its difficult to use, thus I suggest adding another.
One application that can handle many pdf types well is an editor such as Tracker Exchange and integrating 2 way exchange with SumatraPDF you have a fast viewer combined with a reasonable converter.
The best way to use SumatraPDF during conversion is as a previewer and source for manual cut and paste. Such that you can ensure there is 100% near as damit similarity so here converting a page using inline HTML